BeautifulSoup vs. lxml benchmark
Previously, I’ve been using BeautifulSoup whenever I had to parse HTML (for example in my dictionary pDict). But this time I’m working on a larger scale project which involves quite a lot of HTML parsing – and BeautifulSoup disappointed me performance wise. In fact, the project wouldn’t be possible using it. Well, it would be – if I subscribed to half of Amazon EC2(;
Since the project is in stealth mode right now, I can’t say which pages I am referring to, but let me give you these facts:
- ~170kb HTML code
- W3C validation shows about 1300 errors and 2600 warnings per page
Considering this many errors and warnings, I previously thought the job had to be done using BeautifulSoup, because it is known to have a very error resistant parser. In fact, BeautifulSoup doesn’t parse the HTML directly, but splits the tags in tag-soup by applying regular expressions around them. Opposing popular stories this seems to make BeautifulSoup very resilient towards bad code.
However, BeautifulSoup doesn’t perform well on the described files. The task: I need to parse 20 links of a particular class off the page. I put the relevant code in a seperate method and profiled it using cProfile:
cProfile.runctx("self.parse_with_beautifulsoup(html_data)", globals(), locals())
def parse_with_beautifulsoup(html_data):
soup = BeautifulSoup.BeautifulSoup(html_data)
links_res = soup.findAll("a", attrs={"class":"detailsViewLink"})
links = [car_link["href"] for car_link in car_links_res]
Parsing 20 pages, this takes 167s on my small Debian VPS. Thats 8s+ per page. Incredibly long. Thinking of how BeautifulSoup parses, it’s understandable however. The overhead of creating tag-soup and parsing via RegExp leads to a whopping 302’000 method calls for just these four lines of code. I repeat: 302’000 method calls for four lines of code.
Hence, I tried lxml. The corresponding code is:
root = lxml.html.fromstring(html_data)
links_lxml_res = root.cssselect("a.detailsViewLink")
links_lxml = [link.get("href") for link in links_lxml_res]
links_lxml = list(set(links_lxml))
On the 20 pages, this takes only 2.4s. That’s only 0.12s per page. lxml needed only 180 method calls for the job. It runs 70x faster than BeautifulSoup and creates 1600x fewer calls.
When you do a graph of these numbers, the performance difference looks ridiculous. Well, let’s have some fun(;
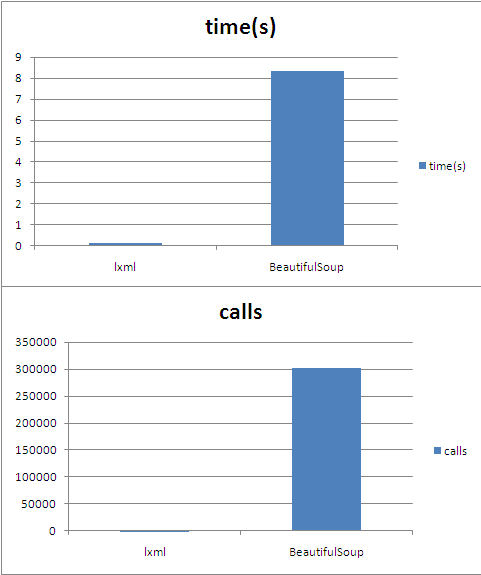
lxml vs BeautifulSoup performance
Considering lxml supports xpath as well, I’m permanently switching my default HTML parsing library.
Note: Ian Bicking wrote a wonderful summary in 2008 on the performance of several Python HTML parsers which led me to lxml and to this article.
Update (08/17/2010): I planned on implementing my results on Google AppEngine. “Unfortunately” lxml relies heavily on C-code (that’s where the speed comes from^^). AppEngine is a pure Python environment. It will never run modules written in C.
Category: articles | Tags: beautifulsoup, cprofile, HTML, lxml, parsing, profile, profiling, python 14 comments »
March 2nd, 2011 at 1:49 pm
hi, what engine is used in Google Chrome / Chromium?
0.12 sec is still too long for me :)
June 1st, 2012 at 3:02 pm
[…] which tries to implement CSS selectors as described in the w3c specification. As a side note, many folks recommend lxml for parsing HTML/XML over BeautifulSoup now, for performance and other […]
August 13th, 2012 at 8:36 am
App Engine Python 2.7 supports lxml.
March 22nd, 2013 at 7:49 am
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
July 24th, 2015 at 7:37 pm
Why generating a list, then a set, then a list of this set?
root = lxml.html.fromstring(html_data)
links_lxml_res = root.cssselect(“a.detailsViewLink”)
links_lxml = list(set(link.get(“href”) for link in links_lxml_res))
Is better
September 29th, 2015 at 3:51 am
[…] BeautifulSoup vs lxml benchmark […]
November 10th, 2015 at 12:23 pm
[…] which tries to implement CSS selectors as described in the w3c specification. As a side note, many folks recommend lxml for parsing HTML/XML over BeautifulSoup now, for performance and other […]
November 26th, 2017 at 3:16 pm
[…] lot of people like BeautifulSoup, but it is pretty slow (another source) and not as good as lxml, which can even use BeautifulSoup as a parser as […]
July 24th, 2019 at 8:45 am
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
October 29th, 2020 at 3:18 am
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
November 12th, 2020 at 6:57 pm
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
December 7th, 2020 at 5:45 am
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
June 26th, 2021 at 11:56 am
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]
March 31st, 2022 at 1:52 pm
[…] http://blog.dispatched.ch/2010/08/16/beautifulsoup-vs-lxml-performance/ […]